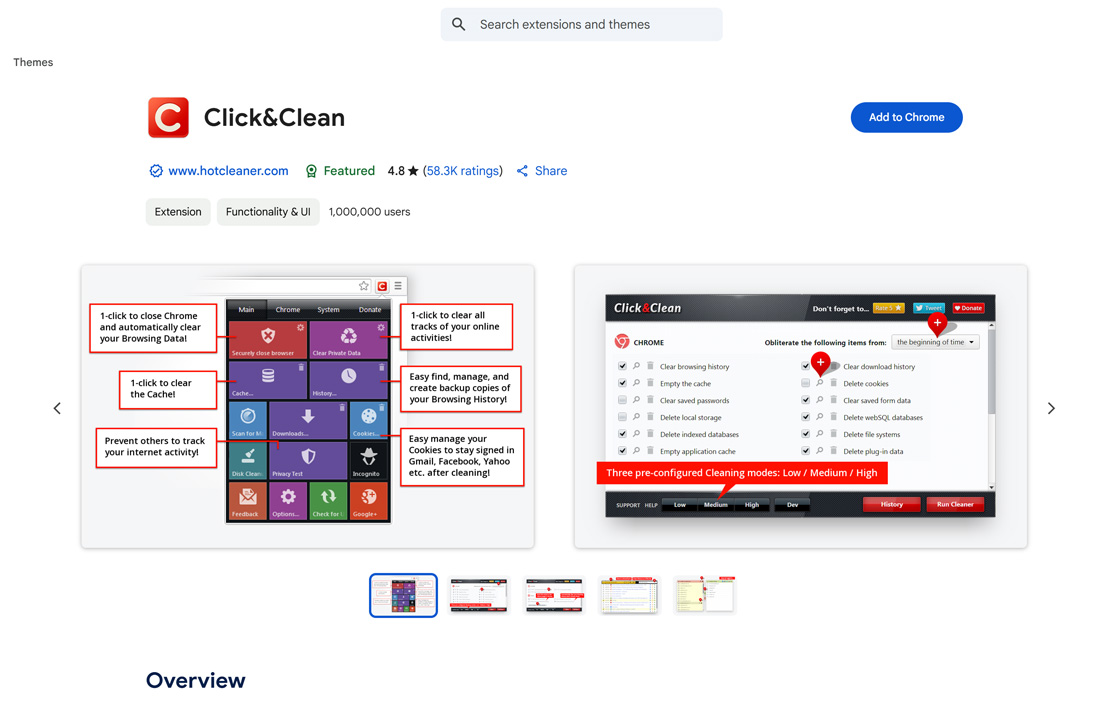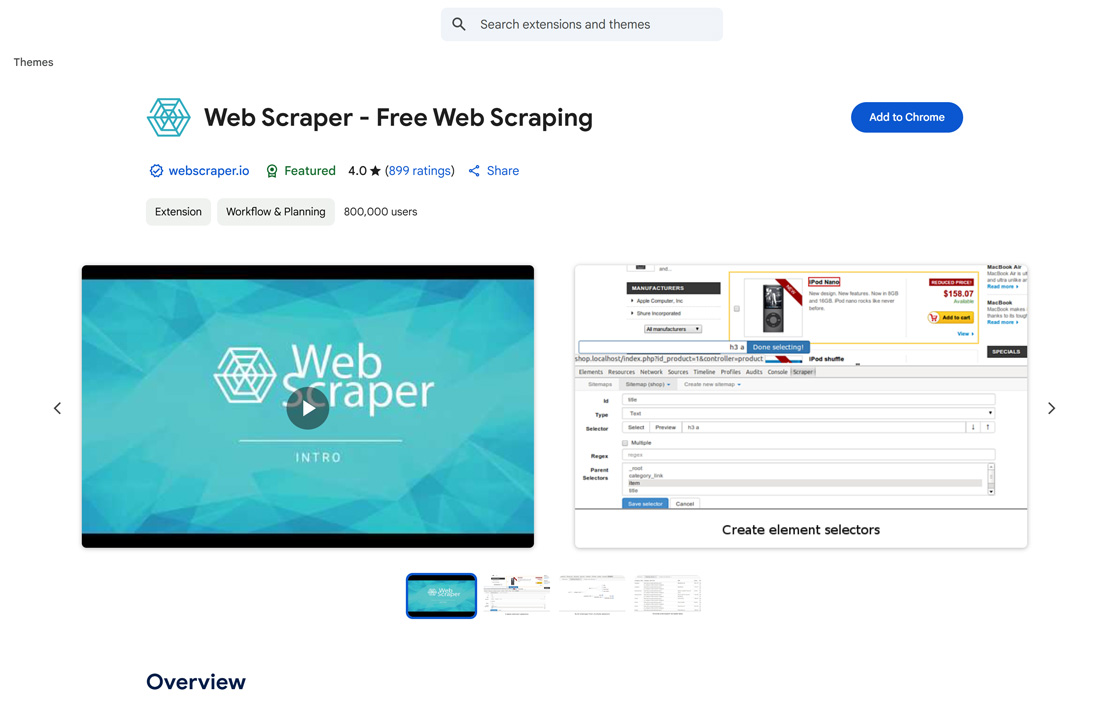
Web Scraper
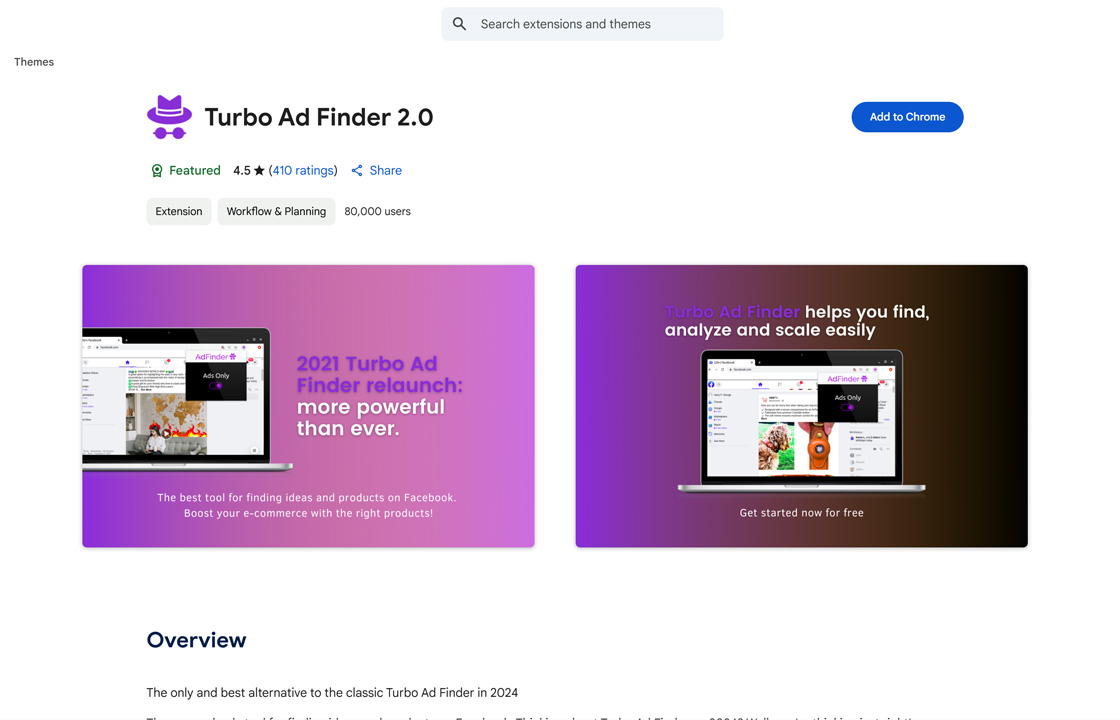
Web Scraper 提供易用的网页数据提取功能,支持多页面抓取、多种数据类型(文本、图片、URL等)、动态页面处理(JavaScript+AJAX、无限滚动)、数据预览、CSV/XLSX/JSON导出和云端自动化抓取(Web Scraper Cloud),通过模块化选择器结构和浏览器内运行,无需额外软件或Python、PHP、JavaScript经验,配备SERP爬取、批量URL处理、代理支持和与Google Sheets、Dropbox、Amazon S3的集成,助力用户高效完成数据挖掘任务。
使用场景:
Web Scraper 适用于营销人员、电商运营者、数据分析师和开发者,用于从TikTok抓取种草视频标题与评论以分析趋势、为亚马逊提取产品价格和描述以监控竞争对手、在速卖通收集多语言用户评价以优化产品页面、通过Shopify分析节日促销页面数据以制定营销策略,或为YouTube户外装备频道爬取观众评论以进行情感分析,覆盖潜在客户挖掘、零售监控、品牌管理、商业情报和机器学习数据收集等场景。
独特优势:
Web Scraper 依托开源架构和点选式界面,提供无代码抓取体验、动态网站适配、精准的多层导航选择器和可扩展的云端自动化功能,支持无限URL抓取(Scale计划)、代理优化(50-300KB/页面)和与Google Analytics、BigQuery的协作,确保用户快速提取结构化数据并显著提升市场研究效率、竞争分析能力和数据驱动决策水平,用户评价其对复杂网站的高适配性和时间节省效果(4.8/5星,69评)。
操作体验:
访问 Chrome Web Store 链接可一键安装扩展,通过开发者工具(需置于屏幕底部)打开Web Scraper选项卡,创建新站点地图、添加数据选择器、运行抓取并导出CSV/XLSX文件,平台提供详细的视频教程、文档、GitHub社区和云端支持(webscraper.io),支持Chrome、Edge等浏览器,建议用户从简单页面开始学习并测试云端功能以优化大规模抓取。

网站流量情况
-
最新流量情况
月浏览量 39
平均访问时长 00:00:00
每次访问页数 1.2
跳出率 46%
-
流量来源
直接访问 1000
自然搜索 00:00:00
外链引荐 1.2
社交媒体 46%
展示广告 46%
-
截止目前所有流量趋势图
-
地理流量分布情况
中国 97.07%
美国 1.2%
新加坡 1.2%
类似产品
-
 AITDK SEO Extension
AITDK SEO Extension
是一款多功能浏览器扩…
是一款多功能浏览器扩展,旨在提供全面的网站分析。凭借其强大的功能,AITDK SEO Extension 可跟踪网站流量、执行 Whois 查询、关键词密度检查并进行 SEO 分析
谷歌插件